hg-store-core-refactor
hg-store-core 重构代码阅读
这个模块主要是增删改查一些功能的实现方法,属于在RocksDB的上层封装。
graph LR
B[hg-store-rocksdb] -->|封装| A[RocksDB]
C[hg-store-core] -->|封装| B
/bussiness 增删改查的主要实现
新增了很多iterator定义,都实现了ScanIterator接口(基本的迭代器,包含hasNext() isValid()这类常用的方法)。
1 | |
关键的业务逻辑都在BussinessImpl中,主要是doGet(),scan()一些方法,这里主要看一下scanIndex()、scan()、doGet()。
doGet()方法函数签名:
public byte[] doGet(String graph, int code, String table, byte[] key) throws HgStoreException利用pdProvider以及传入的code参数RPC来获取当前key所在的分区ID,获取到分区ID之后,利用
KeyCreator存储中实际的Key并创建对应的session直接获取到对应的值。scan()方法scan有多个重载方法
依据起始key,[codeFrom, codeTo) 的扫描
1
ScanIterator scan(String graph, String table, int codeFrom, int codeTo) throws HgStoreException加入scanType参数的扫描方法,scanTypes是一个封装的常量类。
1
2
3
4
5
6
7
8
9
10
11public abstract class Trait {
public static final int SCAN_ANY = 0x80;
public static final int SCAN_PREFIX_BEGIN = 0x01;
public static final int SCAN_PREFIX_END = 0x02;
public static final int SCAN_GT_BEGIN = 0x04;
public static final int SCAN_GTE_BEGIN = 0x0c;
public static final int SCAN_LT_END = 0x10;
public static final int SCAN_LTE_END = 0x30;
public static final int SCAN_KEYONLY = 0x40;
public static final int SCAN_HASHCODE = 0x100;
}这个scan方法会依据code,获取当前graph的所有分区leader ID。
1
ScanIterator scan(String graph, int code, String table, byte[] start,byte[] end, int scanType) throws HgStoreException;指定去重策略的scan方法。
1
ScanIterator scan(String graph, String table, List<QueryTypeParam> params,DeDupOption dedupOption) throws HgStoreException;条件查询的scan
1
ScanIterator scan(String graph, int code, String table, byte[] start, byte[] end, int scanType, byte[] conditionQuery) throws HgStoreException;graph LR A[request] -->|1.query| B[store] -->|2.get Leader Partitions| C[pd] C -->|3.return Leader Partition| B B -->|4.get data| E[RocksDB Session]ScanIndex()按照索引进行扫描,方法签名
1
2
3public ScanIterator scanIndex(String graph, String table, List<List<QueryTypeParam>> params,
DeDupOption dedupOption, boolean lookupBack, boolean transKey,
boolean filterTTL, int limit) throws HgStoreException- 方法的执行流程
graph LR A[only Primary] -->|yes| B[OnlyPrimary] --> D[scan method1] --> E[Prefix Scan or Range Scan] E --> F[prefixScan]-->|condition1|H[scan method2] E --> G[rangeScan]-->|condition2|H A -->|No| Z[mutiple index]scan方法会进一步去查询
partitioinLeaderId,把读写请求转发到Leader上面。
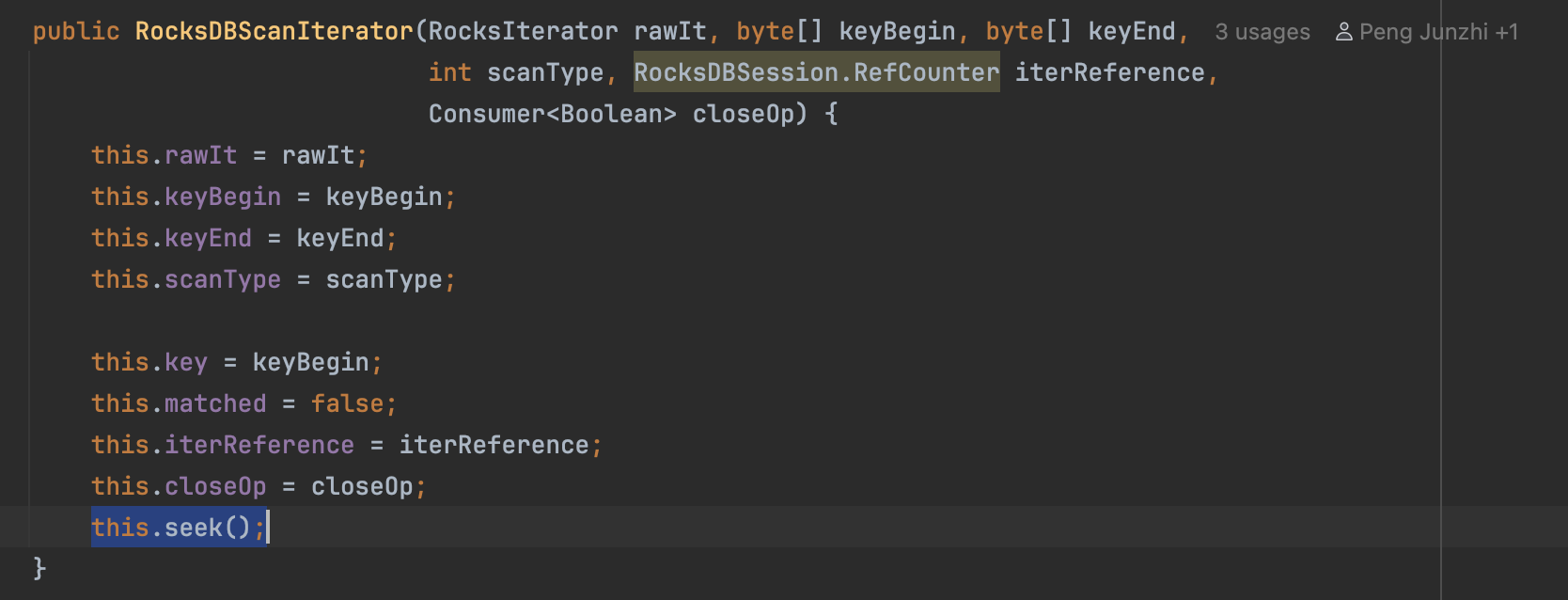
那么最后到底是在哪里调用RocksDB的API来进行范围查询的呢?从流程图里边最后scan方法开始,简单挑一条链路。scan方法最后是通过
rocksDBSession接着返回RocksDBScanIterator,而RocksDBScanIterator的构造方法中有最关键的一步this.seek()方法中进一步调用了RocksDB API中的seek()方法。这里就是从文件中读取到了我们想要的数据。后续我们利用这个RocksDBScanIterator.next()或是一些其他的方法,就可以从我们的文件中读取到数据了~
回到一开始,如果有多个索引项,会进入另一个分支,根据不同的去重策略和查询条件,再会创建不同的
Iterator对象,返回给上层(这里的上层指的是Raft Node,因为core模块更加贴近底层存储,还没有涉及到Raft通信的逻辑,在分布式部署的时候,来自server的读写请求都会经由Leader Node同步给Follower/Learner之后再做响应,这部分在重构了node模块之后再来读~)。doPut()方法
这里的doPut()方法同时有增+改的功能,因为对于对于一般的KV存储,执行put操作就像操作HashMap一样,如果key存在,那么直接覆盖这个value,从而达到了修改的操作;如果key不存在,那么put就是直接新增~下面看一看doPut的源码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18public void doPut(String graph, int code, String table,byte[] key, byte[] value) throws
HgStoreException {
int partId = provider.getPartitionByCode(graph, code).getId();
try (RocksDBSession dbSession = getSession(graph, table, partId)) {
SessionOperator op = dbSession.sessionOp();
try {
op.prepare();
byte[] targetKey = keyCreator.getKeyOrCreate(partId, graph, code, key);
op.put(table, targetKey, value);
op.commit();
} catch (Exception e) {
log.error("Graph " + graph + " doPut exception", e);
op.rollback();
throw new HgStoreException(HgStoreException.EC_RKDB_DOPUT_FAIL, e.toString());
}
}
}这里的封装逻辑很简单,
- 依据 目标图 + code字段,向pd发送请求获取当前数据的分片
- 获取对应的rocksDBSesssion(
getSession()) - 上锁(
op.prepare()) - 调用
getKeyOrCreate(),如果有这个键值,那么返回实际存储的键值;如果没有那么会新创建一个键(实际上rocksDB存储的键值:这里传入的key+一些定位字符串的拼接,最后序列化为二进制,存储的数据结构可以参考下边这个gist https://gist.github.com/imbajin/db4bb02fdd1cf03844ed528108d1dd22) - 执行put操作(
op.put()) - 释放锁(
op.commit()) - 如果插入的过程中有报错,那么执行回滚
/cmd
新增了支持BlankTask、Redirect的任务,调整目录结构把一些原来的request/response移入了新建的/request 和/response目录下,方便管理。
BlankTask的源码就是简单的继承自HgCmdBase.BaseRequest不需要过多的解释了,简单的读一读RedirectTask的源代码:
1 | |
包含两个字段:raftOp和一个data,他的作用是将这个raft重定向给Partition Leader节点。
/meta
重构GraphIdManager(),将原有的GetGraphId()拆分为GetGraphId()以及GetOrCreate()
修改PartitionManager的处理逻辑,新增删除多余分区的存储路径 逻辑
/metric
SystemMetricService中注释掉了一些未使用的方法,主要用来做性能监控。
/options
HgstoreEngineOptions 新增了QueryPushDown字段,用来判断是否是查询下推
/pd
DefaultPdProvider新增成员Processors类,移除了PartitionInstructionListener,利用责任链模式把不同的指令发给不同的processor处理。同时也方便未来的扩展。
在DefaultPdProvider中的监听器部分新增了分片处理的相关方法。
1 | |
partitionHeartbeat(List<Metapb.PartitionStats> statsList)方法,统计所有的分区信息,将信息通过pdPluse.notifyServer()的方式发送给pd节点。
根据
HeartbeatService.java中的实现, PartitionStats 包含:
- 分区ID ( partition.getGroupId() )
- 图名称列表 ( partition.getPartitions().keySet() )
- Leader任期 ( partition.getLeaderTerm() )
- 配置版本 ( partition.getShardGroup().getConfVersion() )
- Leader信息 (当前Store作为Leader的Shard信息)
- 分区状态 (Normal/Offline)
- Shard列表和状态统计
- 时间戳
/raft
新增了DefaultRaftClosure是对RaftClosure的包装,简化 Raft 操作的回调处理,提供统一的封装,后续只要调用这个run()方法即可。
新增PartionStateMachine- 继承自 StateMachineAdapter 的 Raft 状态机实现
- 日志应用处理 : onApply() 方法处理 Raft 日志条目的应用
- Leader 选举管理 :处理 Leader 启动/停止、Follower 状态变化
- 快照管理 :支持快照保存和加载功能
- 状态监听 :支持多个状态监听器和任务处理器
- 配置变更 :处理 Raft 集群配置变更
RaftOperation中新增两个操作类型常量:
DO_SYNC_SNAPSHOT = 0x68:同步快照操作SYNC_BLANK_TASK = 0x69:同步空白任务操作
/listener
这个包是在3.7中新增的,主要包含了三个接口,分别是PartitionChangedListener、PartitionStateListener、StoreStateListener。分别监听三种消息,一是分区变化消息的监听、二是分区状态变化消息的监听、三是store状态变化消息的监听。其中PartitionChangedListener和StoreStateListener由HgStoreEngine实现了,PartitionStateListener由HeartBeatService实现。
在PartitionEngine中存在着调用RaftOption的raftNode.getRaftOptions().setTruncateLog(true);,这里展示一下原始jraft库的实现。
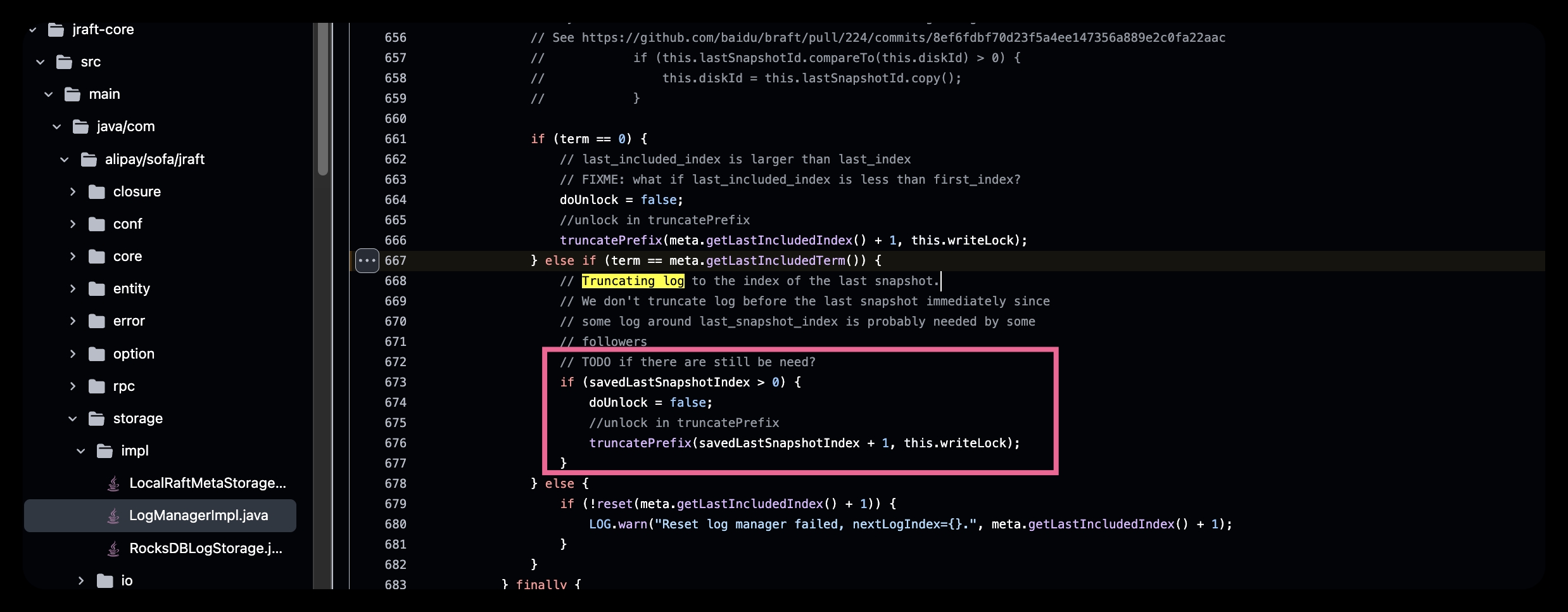
这里的实现是只要snapshot metadata中lastIncludeIndex(这个概念可以参考raft paper https://pdos.csail.mit.edu/6.824/papers/raft-extended.pdf),当raft peer最后一个index的log term 与snapshot相等的时候,且这个图中的条件成立,那么会立刻进行快照。这种方式会造成snapshot过于频繁,因为raft peer term很长一段时间(服务正常运行的时候)大概率是不会增长,这种情况下更希望在到达snapshot阈值的时候进行truncate log的操作,而不是把大量的资源用在同步snapshot。
3.7版本引入了这个控制的变量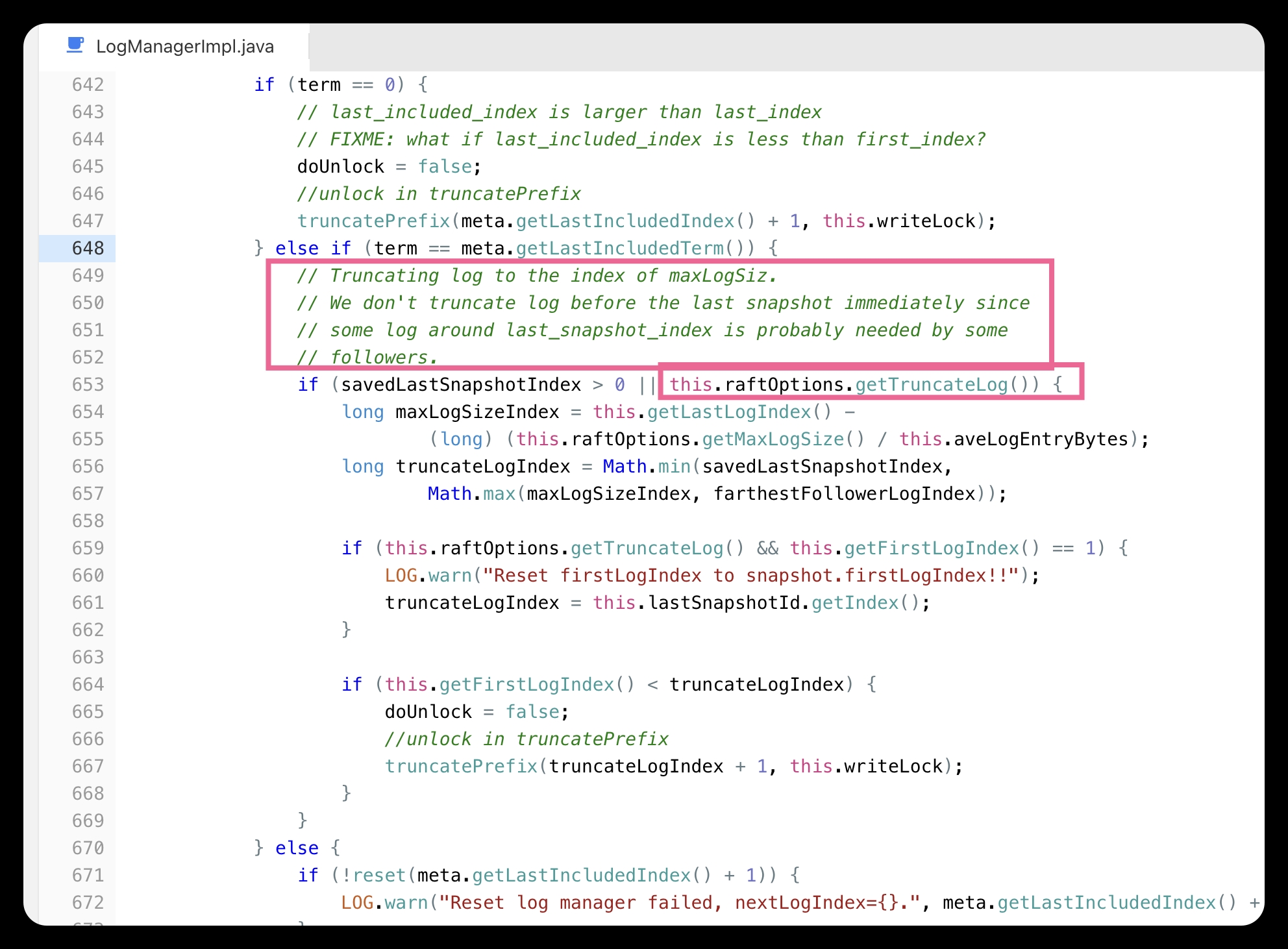
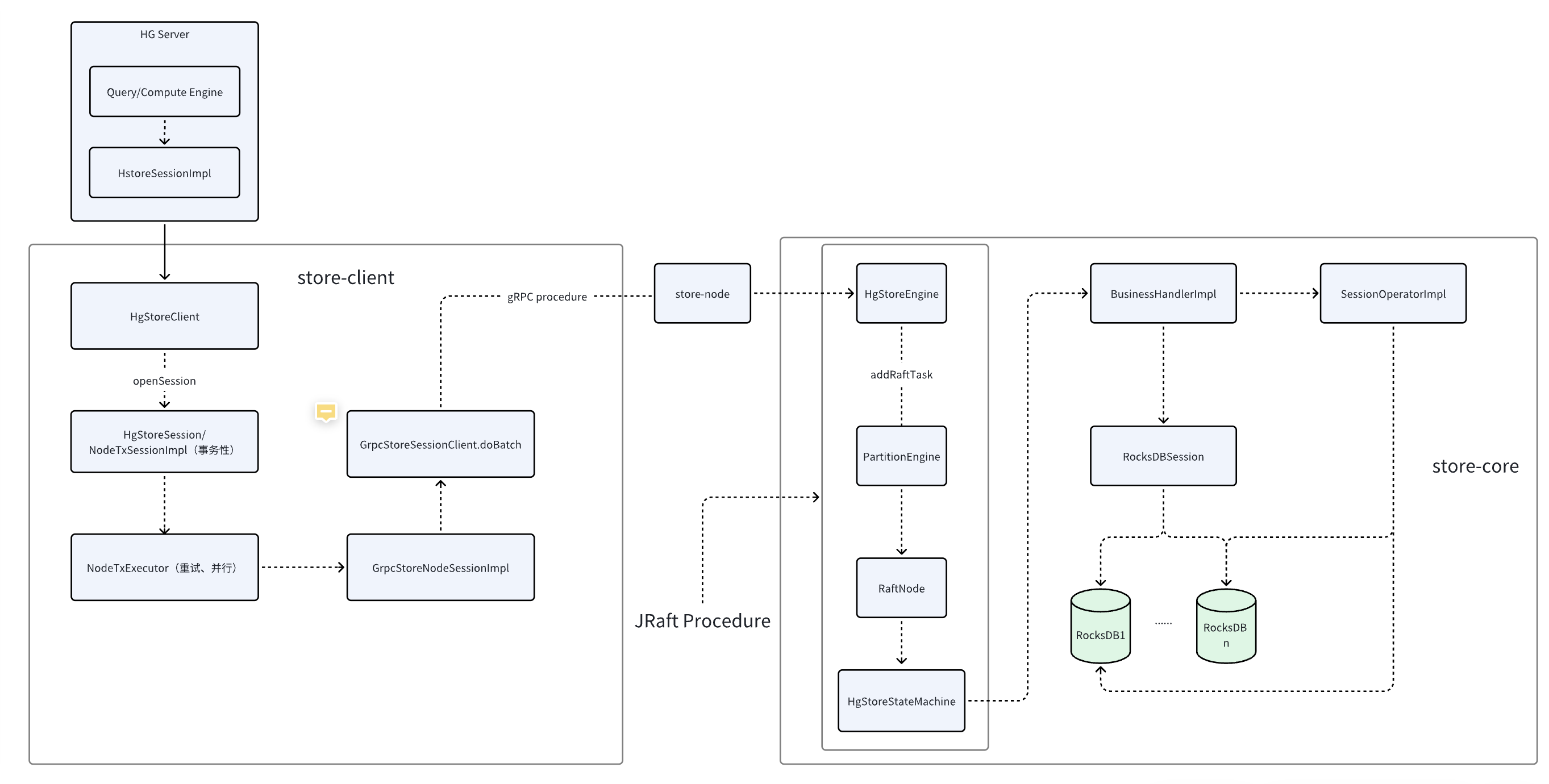
这里贴一下1.5版本的HG分布式store的request flow
(https://www.pengzna.top/article/raft-rocksdb-in-hg/)