HugeGraph重构-store-gRPC模块解析
hg-store-rpc模块
本模块采用了gRPC作为通信协议,为了更好的了解rpc的过程,我们需要先了解一下什么是gRPC。
什么是gRPC
RPC,全称Remote Procedure Call,中文译为远程过程调用。通俗地讲,使用RPC进行通信,调用远程函数就像调用本地函数一样,RPC底层会做好数据的序列化与传输,从而能使我们更轻松地创建分布式应用和服务。
而gRPC是RPC的一种,是由Google免费开源的一个RPC通信协议,我们只需要好API的Request与Response,其余的事情由gRPC帮我们实现。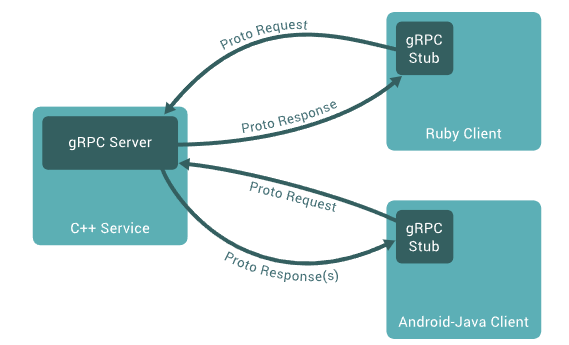
默认的情况下,gRPC使用Protocol Buffers作为接口定义语言(IDL),本质上是一个序列化结构化数据的过程,比如Java中的class或者是cpp中的struct/class的过程,在使用的过程中你也可以使用JSON作为序列化,可以在不同的服务之间进行通信。
简单的来说,gRpc就是一套由Google实现的服务通信框架更多的详细信息可以参考:
https://grpc.org.cn/docs/what-is-grpc/introduction/
gRPC In HugeGraph
作为一个存算分离架构的图数据库,不同的模块需要部署在不同的设备上,那么此时服务间的调用就需要用到RPC,HugeGraph采用了gRPC作为通信框架。
这里主要说明一下store模块的gRPC定义(定义在hugegraph-store/huge-store-grpc这个模块下)
下边是各个.proto文件的含义
1 | |
下面主要关注一下这几个.proto文件的内容
graphpb.proto
文件中首先定义了一个rpc服务
1 | |
这个rpc的请求与响应都以流式传输
请求消息分为两种,分别是初始的扫描请求scan_request,或者是某一个请求的响应。
1
2
3
4
5
6
7
8message ScanPartitionRequest{
//...
RequestHeader header = 1;
oneof request {
Request scan_request = 2;
Reply reply_request = 4;
}
}
接下来是Request的定义,依次指明了扫描的类型,分区信息以及用于过滤一些信息等。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15message Request{
ScanType scan_type = 1;
string graph_name = 2;
uint32 partition_id = 3;
uint32 start_code = 4;
uint32 end_code = 5;
// Filter conditions
string condition = 6;
string table = 7;
int64 limit = 8;
int32 boundary = 9;
bytes position = 10;
// Return condition
repeated int64 properties = 11;
}
响应消息ScanResponse,repeated 关键字表示每次响应是一个列表,而不是一个个的vertex或Edge。
1
2
3
4
5
6
7message ScanResponse{
ResponseHeader header = 1;
// Message Sequence Number
int32 seq_no = 2;
repeated Vertex vertex = 3;
repeated Edge edge = 4;
}
2. healthy.proto
文件中定义了一个简单的Healthy的RPC服务,用于健康检查。
1
2
3
4
5
6
7service Healthy {
rpc IsOk(google.protobuf.Empty) returns (StringReply) {}
}
message StringReply {
string message = 1;
}
3. query.proto –new
这一个是在3.7版本中新增的proto文件,也是store-grpc这一模块的关键更新,这个proto中定义了支持查询下推功能的RPC消息。
首先是服务的定义
1
2
3
4
5service QueryService {
rpc query(stream QueryRequest) returns (stream QueryResponse) {}
rpc query0(QueryRequest) returns (QueryResponse) {}
rpc count(QueryRequest) returns (QueryResponse) {}
}
分别定义了三个RPC服务,一个是以流的形式来接受请求与响应,一个简单的一元 RPC(即一个请求对应一个响应)。它适用于那些预计能快速返回结果的、较小的查询。最后则是一个计数请求,可以看作是对COUNT请求的优化。
query中最关键的部分则是stream QueryRequest这个查询请求。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39message QueryRequest{
string queryId = 1;
string graph = 2;
string table = 3;
repeated AggregateFunc functions = 4;
// 属性剪裁,如果为空,则返回所有的属性, aggregation 作为单独字段,不包含此列
// 如果有group by,应该是group by的子集
repeated bytes property = 5;
repeated bytes group_by = 6; // group by的字段
repeated uint32 having = 7; // having 的过滤
repeated bytes order_by = 8; // order by 字段
bool sort_order = 9; // asc or desc
bool null_property = 10; // 不使用property,仅仅返回key
ScanType scan_type = 11; // 表扫描类型, 如果有索引,此项忽略
repeated ScanTypeParam scan_type_param = 12; // id, prefix 只用到start
DeDupOption dedup_option = 13; // 是否需要key消重
bytes condition = 21; // condition
bytes position = 24; // 返回offset ~ offset + limit
uint32 limit = 23; // page
uint32 offset = 25; // offset
double sample_factor = 31; // 抽样频率,应该小于等于1
repeated bytes olap_property = 32; // 读取的olap 属性
// 使用的索引, 第一层为or关系,第二层为 and关系
// indexes ((index,index) or (index, index))
repeated Index indexes = 41;
bool load_property_from_index = 42;
bool check_ttl = 43;
// 按照element的 label id group by
bool group_by_schema_label = 44;
}
消息中比较重要的是AggregateFunc指明了聚合操作的函数类型,常见的如COUNT、SUM、AVG等;property告诉服务端只需要返回哪些属性(字段),而不是返回整个顶点或边的所有数据,以此减少网络传输量;而group_by、having、order by则类似于Mysql中的类似操作;condition则是指明了过滤条件类比Mysql中的where子句;
最后则是QueryResponse
1
2
3
4
5
6
7message QueryResponse {
string query_id = 1;
bool is_ok = 2;
bool is_finished = 3;
string message = 4;
repeated Kv data = 5;
}
关键字段为is_finished用来标记流式响应是否结束,Kv data则是以K-V的形式返回数据,需要注意的是,如果是聚合操作,那么返回的则会是聚合后的结果。
store_common.proto–updated
这个proto文件主要定义了HugeGraph的gRPC中通用的一些数据结构与枚举类型
- Key: 只包含一个 key 的结构。
- Tkv: “Tabled Key-Value” 的缩写,即带所属表信息的键值对 (table, key, value)。
- Tk: “Tabled Key” 的缩写,即带所属表信息的键 (table, key)。
- Tp: “Tabled Prefix” 的缩写,即带所属表信息的前缀 (table, prefix),用于前缀扫描。
- Tse: “Tabled Start-End” 的缩写,即带所属表信息的范围 (table, start key, end key),用于范围扫描。
在新版本中新添加了一个结构TTLCleanRequest,这个Request用于清理过期的数据,因而需要定位到数据所在的图/分片/表等信息,以及过期数据的IDs。
1
2
3
4
5
6message TTLCleanRequest {
string graph = 1;
int32 partitionId = 2;
string table = 3;
repeated bytes ids = 4;
}
其余的一些枚举则都可以见名知意,这里就不做解释了。